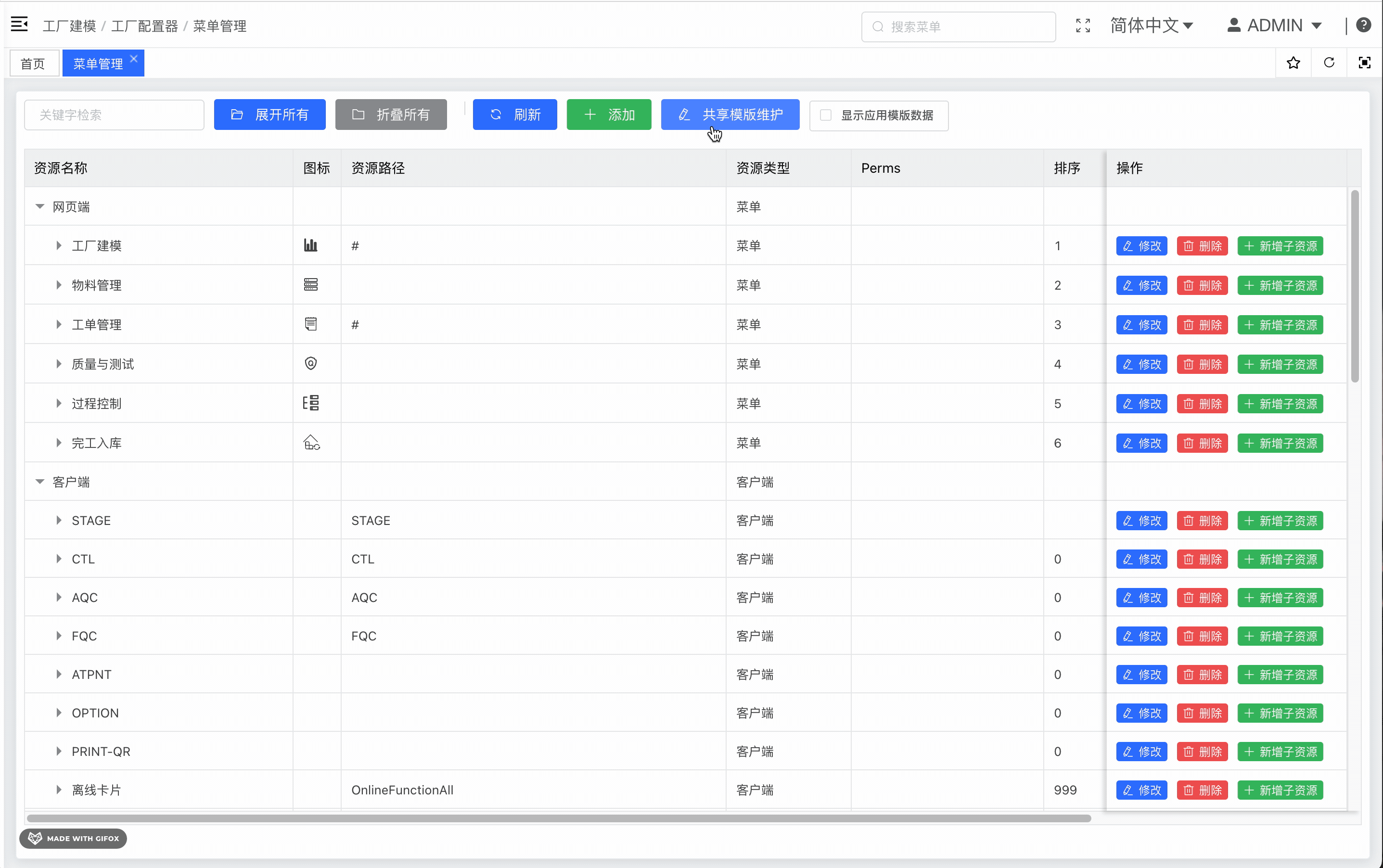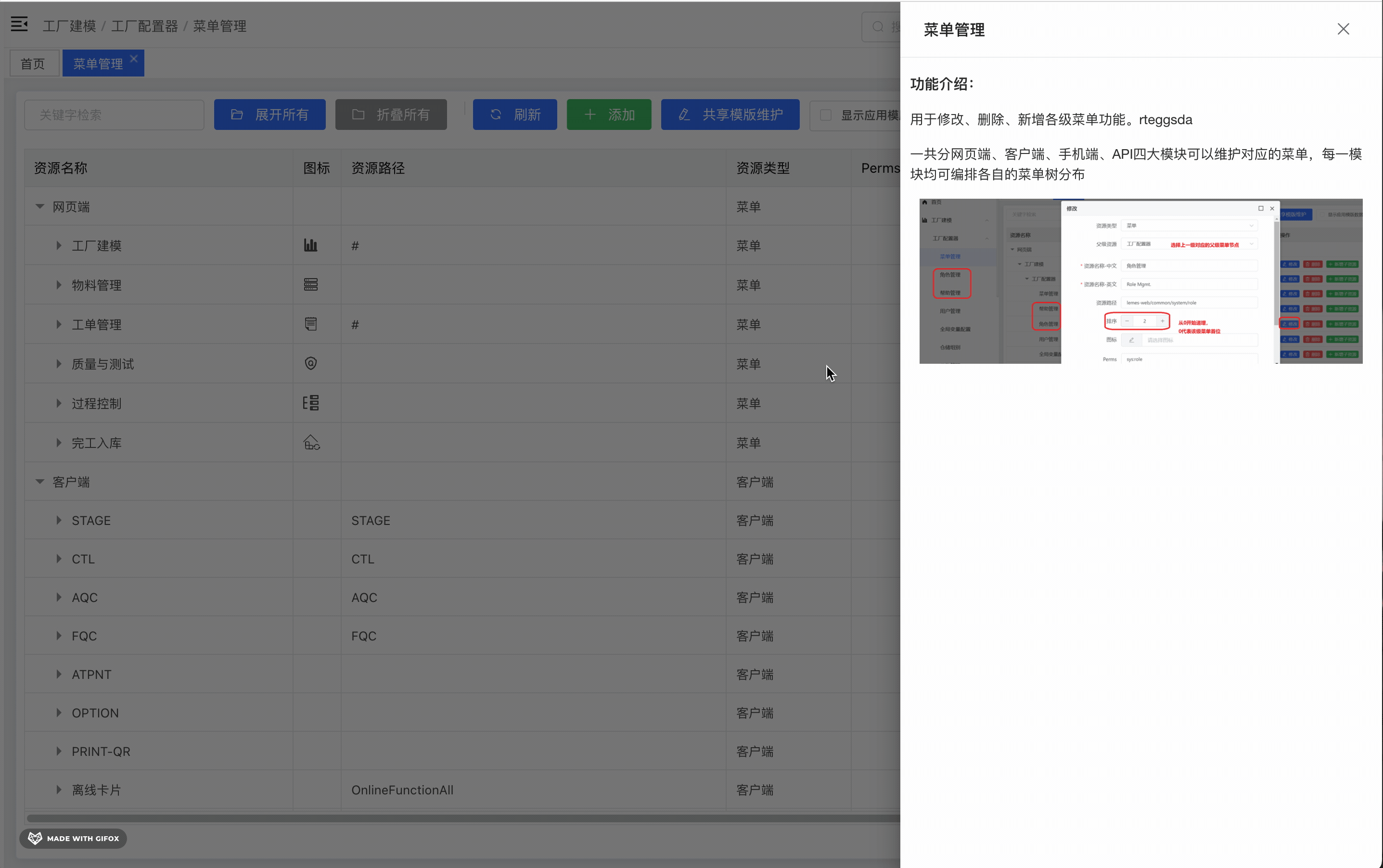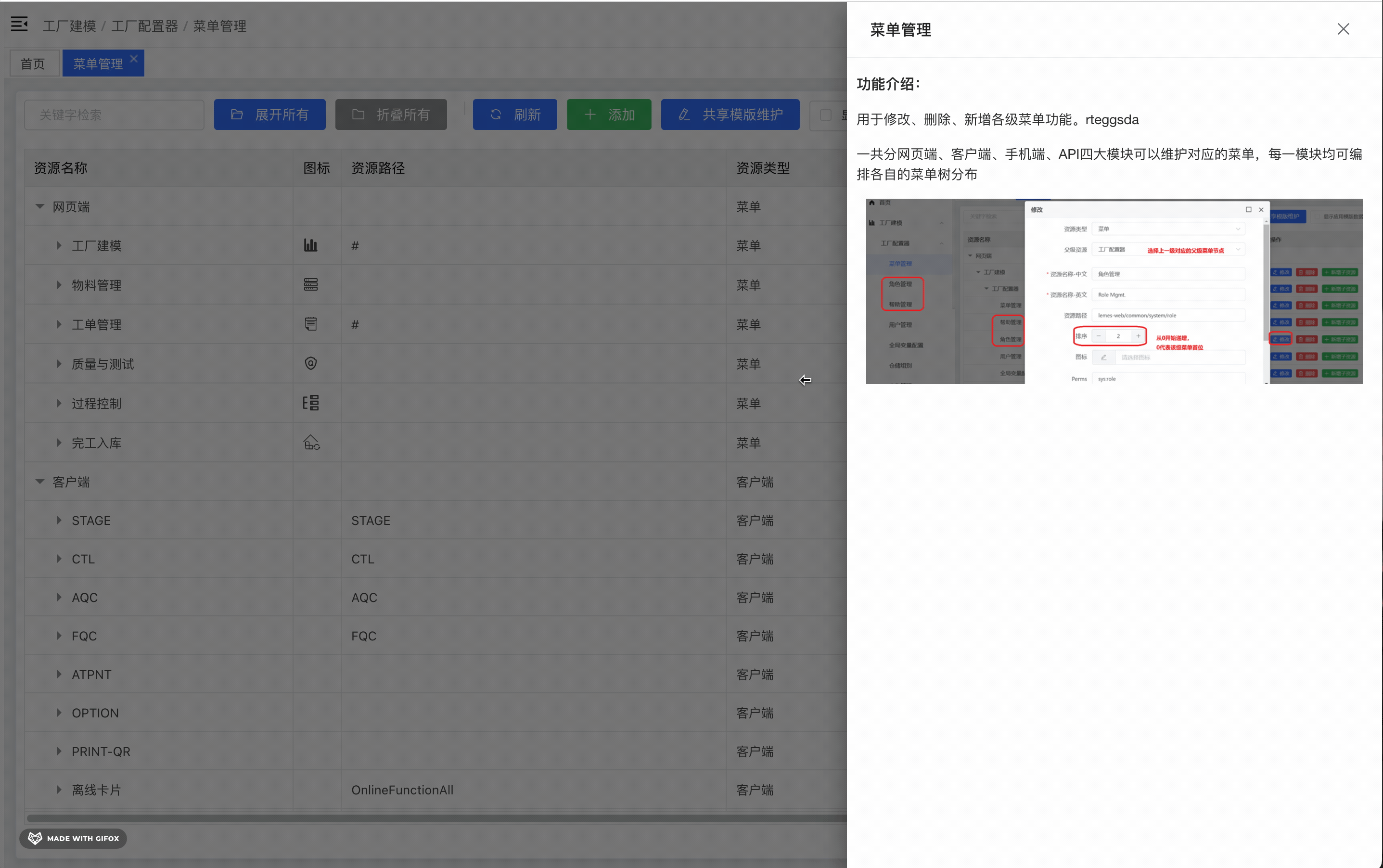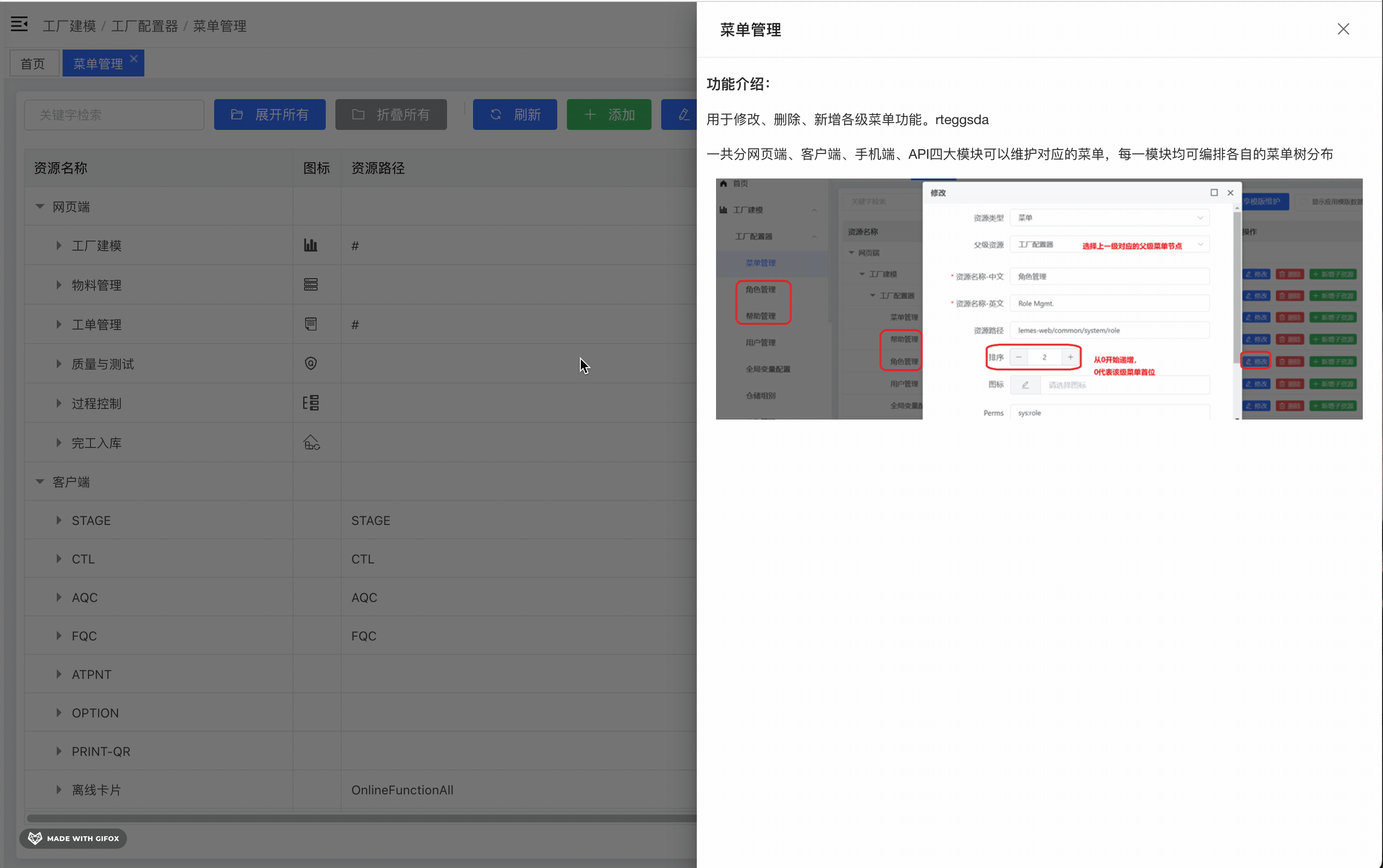
一、概述1.1 什么是docker
Docker 诞生于 2013 年初,由 dotCloud 公司(后改名为 Docker Inc)基于 Go 语言实现并开源的项目。此项目后来加入 Linux基金会,遵从了 Apache 2.0 协议
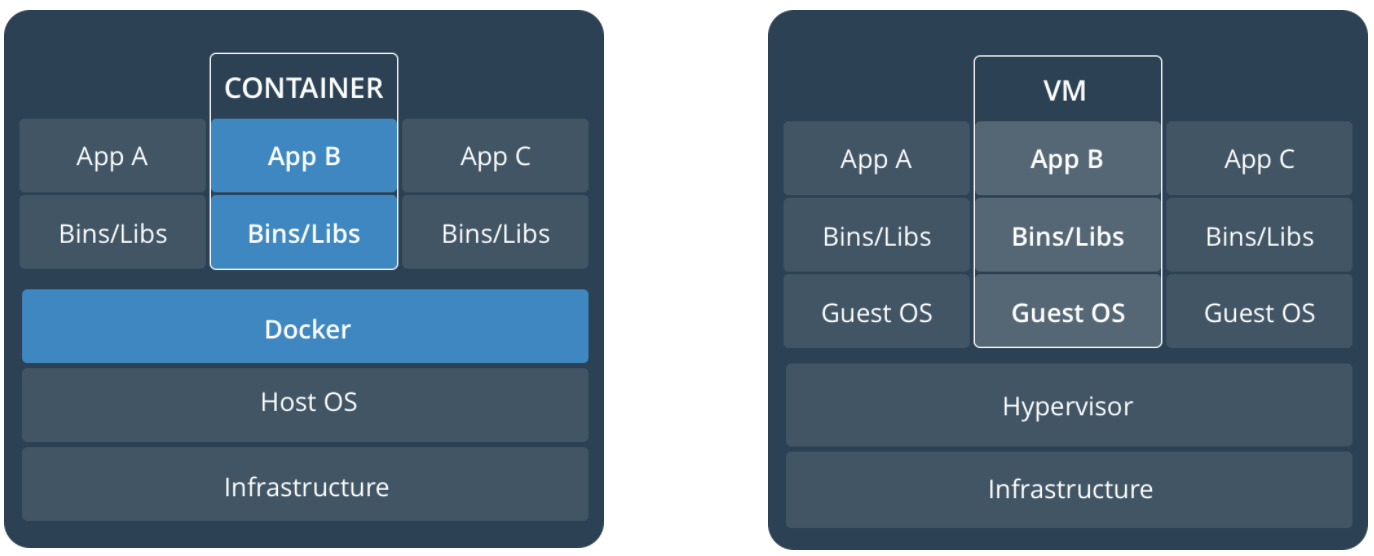
Docker 项目的目标是实现轻量级的操作系统虚拟化解决方案。Docker 是在 Linux 容器技术(LXC)的基础上进行了封装,让用户可以快速并可靠的将应用程序从一台运行到另一台上。
使用容器部署应用被称为容器化,容器化技术的几大优势:
- 灵活:甚至复杂的应用也可以被容器化
- 轻量:容器利用和共享宿主机内核,从而在利用系统资源比虚拟机更加的有效
- 可移植:你可以在本地构建,在云端部署并在任何地方运行
- 松耦合:容器是高度封装和自给自足的,允许你在不破环其他容器的情况下替换或升级任何一个
- 可扩展:你可以通过数据中心来新增和自动分发容器
- 安全:容器依赖强约束和独立的进程
1.2 和传统虚拟机的区别
容器在Linux上本地运行,并与其他容器共享主机的内核。它运行一个离散进程,不占用任何其他可执行文件更多的内存,从而使其轻巧。
1.3 相关链接
官网:https://www.docker.com/
文档:https://docs.docker.com/
二、Image镜像
2.1 介绍
Docker 镜像是一个特殊的文件系统,除了提供容器运行时所需的程序、库、资源、配置等文件外,还包含了一些为运行时准备的一些配置参数(如匿名卷、环境变量、用户等)。镜像不包含任何动态数据,其内容在构建之后也不会被改变。
- 父镜像:每个镜像都可能依赖于有一个或多个下层组成的另一个镜像。下层那个镜像就是上层镜像的父镜像
- 基础镜像:一个没有任何父镜像的镜像,被称为基础镜像
- 镜像ID:所有镜像都是通过一个 64 位十六进制字符串(256 bit 的值)来标识的。为了简化使用,前 12 个自负可以组成一个短ID,可以在命令行中使用。短ID还是有一定的碰撞几率,所以服务器总是返回长ID
2.2 从仓库下载镜像
可以通过 docker pull 命令从仓库获取所需要的镜像
docker pull [选项] [Docker Registry 地址]<镜像名>:<标签>
选项:
- –all-tags,-a : 拉去所有 tagged 镜像
- –disable-content-trust:忽略镜像的校验,默认
- –platform:如果服务器是开启多平台支持的,则需要设置平台
- –quiet,-q:静默执行,不打印详细信息
标签: 下载指定标签的镜像,默认 latest
示例
# 从 Docker Hub 下载最新的 debian 镜像docker pull debian# 从 Docker Hub 下载 jessie 版 debian 镜像docker pull debian:jessie# 下载指定摘要(sha256)的镜像docker pull ubuntu@sha256:45b23dee08af5e43a7fea6c4cf9c25ccf269ee113168c19722f87876677c5cb2
2.3 列出本地镜像
# 列出已下载的镜像 image_name: 指定列出某个镜像docker images [选项] [image_name]
选项
| 参数 | 描述 |
|---|
| –all, -a | 展示所有镜像(包括 intermediate 镜像) |
| –digests | 展示摘要 |
| –filter, -f | 添加过滤条件 |
| –format | 使用 Go 模版更好的展示 |
| –no-trunc | 不删减输出 |
| –quiet, -q | 静默输出,仅仅展示 IDs |
示例
# 展示本地所有下载的镜像docker images# 在本地查找镜像名是 "java" 标签是 "8" 的 奖项docker images: java:8# 查找悬挂镜像docker images --filter "dangling=true"# 过滤 lable 为 "com.example.version" 的值为 0.1 的镜像docker images --filter "label=com.example.version=0.1"
2.4 Dockerfile创建镜像
为了方便分享和快速部署,我们可以使用 docker build 来创建一个新的镜像,首先创建一个文件 Dockerfile,如下
# This is a commentFROM ubuntu:14.04MAINTAINER Chris <jaytp@qq.com>RUN apt-get -qq updateRUN apt-get -qqy install ruby ruby-devRUN gem install sinatra
然后在此 Dockerfile 所在目录执行 docker build -t yelog/ubuntu:v1 . 来生成镜像,所属组织/镜像名:标签
2.5 上传镜像
用户可以通过 docker push 命令,把自己创建的镜像上传到仓库中来共享。例如,用户在 Docker Hub 上完成注册后,可以推送自己的镜像到仓库中。
docker push yelog/ubuntu
2.6 导出和载入镜像
docker 支持将镜像导出为文件,然后可以再从文件导入到本地镜像仓库
# 导出docker load --input yelog_ubuntu_v1.tar# 载入docker load < yelog_ubuntu_v1.tar
2.7 移除本地镜像
# -f 强制删除docker rmi [-f] yelog/ubuntu:v1# 删除悬挂镜像docker rmi $(docker images -f "dangling=true" -q)# 删除所有未被容器使用的镜像docker image prune -a
三、容器
3.1 介绍
容器和镜像,就像面向对象中的 类 和 示例 一样,镜像是静态的定义,容器是镜像运行的实体,容器可以被创建、启动、停止、删除和暂停等
容器的实质是进城,耽于直接的宿主执行的进程不同,容器进程运行于属于自己的独立的命名空间。因此容器可以拥有自己的 root 文件系统、网络配置和进程空间,甚至自己的用户 ID 空间。容器内的进程是运行在一个隔离的环境里,使用起来,就好像是在一个独立于宿主的系统下一样。这种特性使得容器封装的应用比直接在宿主运行更加安全。
3.2 创建容器
我们可以通过命令 docker run 命令创建容器
如下,启动一个容器,执行命令输出 “Hello word”,之后终止容器
docker run ubuntu:14.04 /bin/echo 'Hello world'
下面的命令则是启动一个 bash 终端,允许用户进行交互
docker run -t -i ubuntu:14.04 /bin/bash
-t 让 Dcoker 分配一个伪终端(pseudo-tty)并绑定到容器的标准输入上
-i 责让容器的标准输入保持打开
更多参数可选
| -a stdin | 指定标准输入输出内容类型 |
|---|
| -d | 后台运行容器,并返回容器ID |
| -i | 以交互模式运行容器,通常与 -t 同时使用 |
| -P | 随机端口映射,容器端口内部随即映射到宿主机的端口上 |
| -p | 指定端口映射, -p 宿主机端口:容器端口 |
| -t | 为容器重新分配一个伪输入终,通常与 -i 同时使用 |
| –name=”gate” | 为容器指定一个名称 |
| –dns 8.8.8.8 | 指定容器的 DNS 服务器,默认与宿主机一致 |
| –dns-search example.com | 指定容器 DNS 搜索域名,默认与宿主机一致 |
| -h “gate” | 指定容器的 hostname |
| -e username=’gate’ | 设置环境变量 |
| –env-file=[] | 从指定文件读入环境变量 |
| –cpuset=”0-2” or –cpuset=”0,1,2” | 绑定容器到指定 CPU 运行 |
| -m | 设置容器使用内存最大值 |
| –net=”bridge” | 指定容器的网络连接类型支持 bridge/host/none/container |
| –link=[] | 添加链接到另一个容器 |
| –expose=[] | 开放一个端口或一组端口 |
| –volume,-v | 绑定一个卷 |
当利用 docker run 来创建容器时,Dcoker 在后台运行的标准操作包括:
- 检查本地是否存在指定的镜像,不存在就从公有仓库下载
- 利用镜像创建并启动一个容器
- 分配一个文件系统,并在只读的镜像外面挂在一层可读写层
- 从宿主主机配置的网桥接口中桥接一个虚拟借口到容器中去
- 从地址池配置一个 ip 地址给容器
- 执行用户指定的应用程序
- 执行用户指定的应用程序
- 执行完毕后容器被终止
3.3 启动容器
# 创建一个名为 test 的容器,容器任务是:打印一行 Hello worddocker run --name='test' ubuntu:14.04 /bin/echo 'Hello world'# 查看所有可用容器 [-a]包括终止在内的所有容器docker ps -a# 启动指定 name 的容器docker start test# 重启指定 name 的容器docker restart test# 查看日志运行日志(每次启动的日志均被查询出来)$ docker logs testHello worldHello world
3.4 守护态运行
前面创建的容器都是执行任务(打印Hello world)后,容器就终止了。更多的时候,我们需要让 Docker 容器在后台以守护态(Daemonized)形式运行。此时,可以通过添加 -d 参数来实现
注意:docker是否会长久运行,和 docker run 指定的命令有关
# 创建 docker 后台守护进程的容器docker run --name='test2' -d ubuntu:14.04 /bin/sh -c "while true; do echo hello world; sleep 1; done"# 查看容器$ docker psCONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES237e555d4457 ubuntu:14.04 "/bin/sh -c 'while t…" 52 seconds ago Up 51 seconds test2# 获取容器的输出信息$ docker logs test2hello worldhello worldhello world
3.5 进入容器
上一步我们已经实现了容器守护态长久运行,某些时候需要进入容器进行操作,可以使用 attach 、exec 进入容器。
# 不安全的,ctrl+d 退出时容器也会终止docker attach [容器Name]# 以交互式命令行进入,安全的,推荐使用docker exec -it [容器Name] /bin/bash
命令优化
- 使用
docker exec 命令时,好用,但是命令过长,我们可以通过自定义命令来简化使用 - 创建文件
/user/bin/ctn 命令文件,内容如下
docker exec -it $1 /bin/bash
- 检查环境变量有没有配置目录
/usr/bin (一般是有配置在环境变量里面的,不过最好再确认一下)
$PATHbash: /usr/local/bin:/usr/bin:/bin:/usr/local/games:/usr/games: No such file or directory
- 完成上面步骤后,就可以直接通过命令
ctn 来进入容器
注意:如果是使用非 root 账号创建的命令,而 docker 命令是 root 权限,可能存在权限问题,可以通过设置 chmod 777 /usr/bin/ctn 设置权限,使用 sudo ctn [容器Name] 即可进入容器
$ ctn [容器Name]
- 使用上面命令时,容器Name 需要手动输入,容器出错。我们可以借助
complete 命令来补全 容器Name,在 ~/.bashrc (作用于当前用户,如果想要所要用户上校,可以修改 /etc/bashrc)文件中添加一行,内容如下。保存后执行 source ~/.bashrc 使之生效,之后我们输入 ctn 后,按 tab 就会提示或自动补全容器名了了
# ctn auto completecomplete -W "$(docker ps --format"{{.Names}}")" ctn
注意: 由于提示的 容器Name 是 ~/.bashrc 生效时的列表,所有如果之后 docker 容器列表有变动,需要重新执行 source ~/.bashrc 使之更新提示列表
3.6 终止容器
通过 docker stop [容器Name] 来终止一个运行中的容器
# 终止容器名为 test2 的容器docker stop test2# 查看正在运行中的容器docker ps# 查看所有容器(包括终止的)docker ps -a
3.7 将容器保存为镜像
我们修改一个容器后,可以经当前容器状态打包成镜像,方便下次直接通过镜像仓库生成当前状态的容器。
# 创建容器docker run -t -i training/sinatra /bin/bash# 添加两个应用gem install json# 将修改后的容器打包成新的镜像docker commit -m "Added json gem" -a "Docker Newbee" 0b2616b0e5a8 ouruser/sinatra:v2
3.8 导出/导入容器
容器 ->导出> 容器快照文件 ->导入> 本地镜像仓库 ->新建> 容器
$ docker ps -aCONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES2a8bffa405c8 ubuntu:14.04 "/bin/sh -c 'while t…" About an hour ago Up 3 seconds test2# 导出$ docker export 2a8bffa405c8 > ubuntu.tar# 导入为镜像$ docker ubuntu.tar | docker import - test/ubuntu:v1.0# 从指定 URL 或者某个目录导入$ docker import http://example.com/exampleimage.tgz example/imagerepo
注意:用户既可以通过 docker load 来导入镜像存储文件到本地镜像仓库,也可以使用 docker import 来导入一个容器快找到本地镜像仓库,两者的区别在于容器快照将丢失所有的历史记录和元数据信息,仅保存容器当时的状态,而镜像存储文件将保存完成的记录,体积要更大。所有容器快照文件导入时需要重新指定标签等元数据信息。
3.9 删除容器
可以使用 docker rm [容器Name] 来删除一个终止状态的容器,如果容器还未终止,可以先使用 docker stop [容器Name] 来终止容器,再进行删除操作
docker rm test2# 删除容器 -f: 强制删除,无视是否运行$ docker [-f] rm myubuntu# 删除所有已关闭的容器$ docker rm $(docker ps -a -q)
3.10 查看容器状态
docker stats $(docker ps --format={{.Names}})
四、数据卷
4.1 介绍
数据卷是一个可供一个或多个容器使用的特殊目录,它绕过 UFS,可以提供很多特性:
- 数据卷可以在容器之间共享和重用
- 对数据卷的修改会立马生效
- 对数据卷的更新,不会影响镜像
- 卷会一直存在,直到没有容器使用
数据卷类似于 Linux 下对目录或文件进行 mount
4.2 创建数据卷
在用 docker run 命令的时候,使用 -v 标记来创建一个数据卷并挂在在容器里,可同时挂在多个。
# 创建一个 web 容器,并加载一个数据卷到容器的 /webapp 目录docker run -d -P --name web -v /webapp training/webapp python app.py# 挂载一个宿主机目录 /data/webapp 到容器中的 /opt/webappdocker run -d -P --name web -v /src/webapp:/opt/webapp training/webapp python app.py# 默认是读写权限,也可以指定为只读docker run -d -P --name web -v /src/webapp:/opt/webapp:ro# 挂载单个文件docker run --rm -it -v ~/.bash_history:/.bash_history ubuntu /bin/bash
4.3 数据卷容器
如果需要多个容器共享数据,最好创建数据卷容器,就是一个正常的容器,撰文用来提供数据卷供其他容器挂载的
# 创建一个数据卷容器 dbdatadocker run -d -v /dbdata --name dbdata training/postgres echo Data-only container for postgres# 其他容器挂载 dbdata 容器的数据卷docker run -d --volumes-from dbdata --name db1 training/postgresdocker run -d --volumes-from dbdata --name db2 training/postgres
五、网络
5.1 外部访问容器
在容器内运行一些服务,需要外部可以访问到这些服务,可以通过 -P 或 -p 参数来指定端口映射。
当使用 -P 标记时,Docker 会随即映射一个 49000~49900 的端口到内部容器开放的网络端口。
使用 docker ps 可以查看端口映射情况
$ docker psCONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES7f43807dc042 training/webapp "python app.py" 3 seconds ago Up 2 seconds 0.0.0.0:32770->5000/tcp amazing_liskov
-p 指定端口映射,支持格式 ip:hostPort:containerPort | ip::containerPort | hostPort:containerPort
# 不限制ip访问docker run -d -p 5000:5000 training/webapp python app.py# 只允许宿主机回环地址访问docker run -d -p 127.0.0.1:5000:5000 training/webapp python app.py# 宿主机自动分配绑定端口docker run -d -p 127.0.0.1::5000 training/webapp python app.py# 指定 udp 端口docker run -d -p 127.0.0.1:5000:5000/udp training/webapp python app.py# 指定多个端口映射docker run -d -p 5000:5000 -p 3000:80 training/webapp python app.py# 查看映射端口配置$ docker port amazing_liskov5000/tcp -> 0.0.0.0:32770
5.2 容器互联
容器除了跟宿主机端口映射外,还有一种容器间交互的方式,可以在源/目标容器之间建立一个隧道,目标容器可以看到源容器指定的信息。
可以通过 --link name:alias 来连接容器,下面就是 “web容器连接db容器” 的例子
# 创建 容器dbdocker run -d --name db training/postgres# 创建 容器web 并连接到 容器dbdocker run -d -P --name web --link db:db training/webapp python app.py# 进入 容器web,测试连通性$ ctn web$ ping dbPING db (172.17.0.3) 56(84) bytes of data.64 bytes from db (172.17.0.3): icmp_seq=1 ttl=64 time=0.254 ms64 bytes from db (172.17.0.3): icmp_seq=2 ttl=64 time=0.190 ms64 bytes from db (172.17.0.3): icmp_seq=3 ttl=64 time=0.389 ms
5.3 访问控制
容器想要访问外部网络,需要宿主机的转发支持。在 Linux 系统中,通过以下命令检查是否打开
$ sysctl net.ipv4.ip_forwardnet.ipv4.ip_forward = 1
如果是 0,说明没有开启转发,则需要手动打开。
$ sysctl -w net.ipv4.ip_forward=1
5.4 配置 docker0 桥接
Docker 服务默认会创建一个 docker0 网桥,他在内核层连通了其他物理或虚拟网卡,这就将容器和主机都放在同一个物理网络。
Docker 默认制定了 docker0 接口的IP地址和子网掩码,让主机和容器间可以通过网桥相互通信,他还给了 MTU(接口允许接收的最大单元),通常是 1500 Bytes,或宿主机网络路由上支持的默认值。这些都可以在服务启动的时候进行配置。
--bip=CIDR ip地址加子网掩码格式,如 192.168.1.5/24--mtu=BYTES 覆盖默认的 Docker MTU 配置
可以通过 brctl show 来查看网桥和端口连接信息
5.5 网络配置文件
Docker 1.2.0 开始支持在运行中的容器里编辑 /etc/hosts 、/etc/hostsname 和 /etc/resolve.conf 文件,修改都是临时的,重新容器将会丢失修改,通过 docker commit 也不会被提交。
六、Dockerfile
6.1 介绍
Dockerfile 是由一行行命令组成的命令集合,分为四个部分:
- 基础镜像信息
- 维护着信息
- 镜像操作指令
- 容器启动时执行指令
如下:
# 最前面一般放这个 Dockerfile 的介绍、版本、作者及使用说明等# This dockerfile uses the ubuntu image# VERSION 2 - EDITION 1# Author: docker_user# Command format: Instruction [arguments / command] ..# 使用的基础镜像,必须放在非注释第一行FROM ubuntu# 维护着信息信息: 名字 联系方式MAINTAINER docker_user docker_user@email.com# 构建镜像的命令:对镜像做的调整都在这里RUN echo "deb http://archive.ubuntu.com/ubuntu/ raring main universe" >> /etc/apt/sources.listRUN apt-get update && apt-get install -y nginxRUN echo "\ndaemon off;" >> /etc/nginx/nginx.conf# 创建/运行 容器时的操作指令 # 可以理解为 docker run 后跟的运行指令CMD /usr/sbin/nginx
6.2 指令
指令一般格式为 INSTRUCTION args,包括 FORM 、 MAINTAINER 、RUN 等
| FORM | 第一条指令必须是 FORM 指令,并且如果在同一个Dockerfile 中创建多个镜像,可以使用多个 FROM 指令(每个镜像一次) | FORM ubuntuFORM ubuntu:14.04 |
|---|
| MAINTAINER | 维护者信息 | MAINTAINER Chris xx@gmail.com |
| RUN | 每条 RUN 指令在当前镜像基础上执行命令,并提交为新的镜像。当命令过长时可以使用 \ 来换行 | 在 shell 终端中运行命令RUN apt-get update && apt-get install -y nginx在 exec 中执行:RUN ["/bin/bash", "-c", "echo hello"] |
| CMD | 指定启动容器时执行的命令,每个 Dockerfile 只能有一条 CMD 命令。如果指定了多条命令,只有最后一条会被执行。 | CMD ["executable","param1","param2"] 使用 exec 执行,推荐方式;CMD command param1 param2 在 /bin/sh 中执行,提供给需要交互的应用;CMD ["param1","param2"] 提供给 ENTRYPOINT 的默认参数; |
| EXPOSE | 告诉服务端容器暴露的端口号, | EXPOSE |
| ENV | 指定环境变量 | ENV PG_MAJOR 9.3ENV PATH /usr/local/postgres-$PG_MAJOR/bin:$PATH |
| ADD | ADD 该命令将复制指定的 到容器中的 。其中 可以是 Dockerfile 所在目录的一个相对路径,也可以是一个URL;还可以是一个 tar文件(自动解压为目录) | |
| COPY | 格式为 COPY 复制本地主机的 (为 Dockerfile 所在目录的相对路径)到容器中的 。当使用本地目录为源目录时,推荐使用 COPY | |
| ENTRYPOINT | 配置容器启动执行的命令,并且不可被 docker run 提供的参数覆盖每个Docekrfile 中只能有一个 ENTRYPOINT ,当指定多个时,只有最后一个起效 | 两种格式ENTRYPOINT ["executable", "param1", "param2"]``ENTRYPOINT command param1 param2(shell中执行) |
| VOLUME | 创建一个可以从本地主机或其他容器挂载的挂载点,一般用来存放数据库和需要保持的数据等。 | VOLUME [“/data”] |
| USER | 指定运行容器时的用户名或 UID,后续的 RUN 也会使用指定用户 | USER daemon |
| WORKDIR | 为后续的 RUN、CMD、ENTRYPOINT 指令配置工作目录。可以使用多个 WORKDIR 指令,后续命令如果参数是相对路径,则会基于之前命令指定的路径。 | 格式为 WORKDIR /path/to/workdir。 WORKDIR /aWORKDIR bWORKDIR cRUN pwd最后的路径为 /a/b/c |
| ONBUILD | 配置当所创建的镜像作为其它新创建镜像的基础镜像时,所执行的操作指令。 | 格式为 ONBUILD [INSTRUCTION]。 |
6.3 创建镜像
编写完成 Dockerfile 之后,可以通过 docker build 命令来创建镜像
docker build [选项] 路径 该命令江都区指定路径下(包括子目录)的Dockerfile,并将该路径下所有内容发送给 Docker 服务端,有服务端来创建镜像。可以通过 .dockerignore 文件来让 Docker 忽略路径下的目录与文件
# 使用 -t 指定镜像的标签信息docker build -t myrepo/myimage .
七、Docker Compose
7.1 介绍
Docker Compose 是 Docker 官方编排项目之一,负责快速在集群中部署分布式应用。维护地址:https://github.com/docker/compose,由 Python 编写,实际调用 Docker提供的API实现。
Dockerfile 可以让用户管理一个单独的应用容器,而 Compose 则允许用户在一个模版(YAML格式)中定义一组相关联的应用容器(被称为一个project/项目),例如一个 web容器再加上数据库、redis等。
7.2 安装
# 使用 pip 进行安装pip install -U docker-compose# 查看用法docker-ompose -h# 添加 bash 补全命令curl -L https://raw.githubusercontent.com/docker/compose/1.2.0/contrib/completion/bash/docker-compose > /etc/bash_completion.d/docker-compose
7.3 使用
术语
- 服务/service: 一个应用容器,实际上可以运行多个相同镜像的实例
- 项目/project: 有一组关联的应用容器组成的完成业务单元
示例:创建一个 Haproxy 挂载三个 Web 容器
创建一个 compose-haproxy-web 目录,作为项目工作目录,并在其中分别创建两个子目录: haproxy 和 web 。
compose-haproxy-webcompose-haproxy-webgit clone https://github.com/yelog/compose-haproxy-web.git
目录长这样:
compose-haproxy-web├── docker-compose.yml├── haproxy│ └── haproxy.cfg└── web ├── Dockerfile ├── index.html └── index.py
在该目录执行 docker-compose up 命令,会整合输出所有容器的输出
$ docker-compose upStarting compose-haproxy-web_webb_1 ... doneStarting compose-haproxy-web_webc_1 ... doneStarting compose-haproxy-web_weba_1 ... doneRecreating compose-haproxy-web_haproxy_1 ... doneAttaching to compose-haproxy-web_webb_1, compose-haproxy-web_weba_1, compose-haproxy-web_webc_1, compose-haproxy-web_haproxy_1haproxy_1 | [NOTICE] 244/131022 (1) : haproxy version is 2.2.2haproxy_1 | [NOTICE] 244/131022 (1) : path to executable is /usr/local/sbin/haproxyhaproxy_1 | [ALERT] 244/131022 (1) : parsing [/usr/local/etc/haproxy/haproxy.cfg:14] : 'listen' cannot handle unexpected argument ':70'.haproxy_1 | [ALERT] 244/131022 (1) : parsing [/usr/local/etc/haproxy/haproxy.cfg:14] : please use the 'bind' keyword for listening addresses.haproxy_1 | [ALERT] 244/131022 (1) : Error(s) found in configuration file : /usr/local/etc/haproxy/haproxy.cfghaproxy_1 | [ALERT] 244/131022 (1) : Fatal errors found in configuration.compose-haproxy-web_haproxy_1 exited with code 1
此时访问本地的 80 端口,会经过 haproxy 自动转发到后端的某个 web 容器上,刷新页面,可以观察到访问的容器地址的变化。
7.4 命令说明
大部分命令都可以运行在一个或多个服务上。如果没有特别的说明,命令则应用在项目所有的服务上。
执行 docker-compose [COMMAND] --help 查看具体某个命令的使用说明
使用格式
docker-compose [options] [COMMAND] [ARGS...]
| build | 构建/重建服务服务一旦构建后,将会带上一个标记名,例如 web_db可以随时在项目目录运行 docker-compose build 来重新构建服务 |
|---|
| help | 获得一个命令的信息 |
| kill | 通过发送 SIGKILL 信号来强制停止服务容器,支持通过参数来指定发送信号,例如docker-compose kill -s SIGINT |
| logs | 查看服务的输出 |
| port | 打印绑定的公共端口 |
| ps | 列出所有容器 |
| pull | 拉去服务镜像 |
| rm | 删除停止的服务容器 |
| run | 在一个服务上执行一个命令docker-compose run ubuntu ping docker.com |
| scale | 设置同一个服务运行的容器个数通过 service=num 的参数来设置数量docker-compose scale web=2 worker=3 |
| start | 启动一个已经存在的服务容器 |
| stop | 停止一个已经运行的容器,但不删除。可以通过 docker-compose start 再次启动 |
| up | 构建、创建、启动、链接一个服务相关的容器链接服务都将被启动,除非他们已经运行docker-compose up -d 将后台运行并启动docker-compose up 已存在容器将会重新创建docker-compose up --no-recreate 将不会重新创建容器 |
7.5 环境变量
环境变量可以用来配置 Compose 的行为
以 Docker_ 开头的变量用来配置 Docker 命令行客户端使用的一样
| COMPOSE_PROJECT_NAME | 设置通过 Compose 启动的每一个容器前添加的项目名称,默认是当前工作目录的名字。 |
|---|
| COMPOSE_FILE | 设置要使用的 docker-compose.yml 的路径。默认路径是当前工作目录。 |
| DOCKER_HOST | 设置 Docker daemon 的地址。默认使用 unix:///var/run/docker.sock,与 Docker 客户端采用的默认值一致。 |
| DOCKER_TLS_VERIFY | 如果设置不为空,则与 Docker daemon 交互通过 TLS 进行。 |
| DOCKER_CERT_PATH | 配置 TLS 通信所需要的验证(ca.pem、cert.pem 和 key.pem)文件的路径,默认是 ~/.docker 。 |
7.6 docker-compose.yml
默认模版文件是 docker-compose.yml ,启动定义了每个服务都必须经过 image 指令指定镜像或 build 指令(需要 Dockerfile) 来自动构建。
其他大部分指令跟 docker run 类似
如果使用 build 指令,在 Dockerfile 中设置的选项(如 CMD 、EXPOSE 等)将会被自动获取,无需在 docker-compose.yml 中再次设置。
**image**
指定镜像名称或镜像ID,如果本地仓库不存在,将尝试从远程仓库拉去此镜像
image: ubuntuimage: orchardup/postgresqlimage: a4bc65fd**build**
指定 Dockerfile 所在文件的路径。Compose 将利用它自动构建这个镜像,然后使用这个镜像。
build: /path/to/build/dir**command**
覆盖容器启动默认执行命令
command: bundle exec thin -p 3000**links**
链接到其他服务中的容器,使用服务名称或别名
links: - db - db:database - redis
别名会自动在服务器中的 /etc/hosts 里创建。例如:
172.17.2.186 db172.17.2.186 database172.17.2.187 redis**external_links**
连接到 docker-compose.yml 外部的容器,甚至并非 Compose 管理的容器。
external_links: - redis_1 - project_db_1:mysql - project_db_1:postgresql
ports
暴露端口信息 HOST:CONTAINER
格式或者仅仅指定容器的端口(宿主机会随机分配端口)
ports: - "3000" - "8000:8000" - "49100:22" - "127.0.0.1:8001:8001"
注:当使用 HOST:CONTAINER 格式来映射端口时,如果你使用的容器端口小于 60 你可能会得到错误得结果,因为 YAML 将会解析 xx:yy 这种数字格式为 60 进制。所以建议采用字符串格式。
**expose**
暴露端口,但不映射到宿主机,只被连接的服务访问
expose: - "3000" - "8000"
volumes
卷挂载路径设置。可以设置宿主机路径 (HOST:CONTAINER) 或加上访问模式 (HOST:CONTAINER:ro)。
volumes: - /var/lib/mysql - cache/:/tmp/cache - ~/configs:/etc/configs/:ro
**
**
volumes_from
从另一个服务或容器挂载它的所有卷。
volumes_from: - service_name - container_name
environment
设置环境变量。你可以使用数组或字典两种格式。
只给定名称的变量会自动获取它在 Compose 主机上的值,可以用来防止泄露不必要的数据。
environment: RACK_ENV: development SESSION_SECRET:environment: - RACK_ENV=development - SESSION_SECRET
env_file
从文件中获取环境变量,可以为单独的文件路径或列表。
如果通过 docker-compose -f FILE 指定了模板文件,则 env_file 中路径会基于模板文件路径。
如果有变量名称与 environment 指令冲突,则以后者为准。
env_file: .envenv_file: - ./common.env - ./apps/web.env - /opt/secrets.env
环境变量文件中每一行必须符合格式,支持 # 开头的注释行。
# common.env: Set Rails/Rack environmentRACK_ENV=development
extends
基于已有的服务进行扩展。例如我们已经有了一个 webapp 服务,模板文件为 common.yml。
# common.ymlwebapp: build: ./webapp environment: - DEBUG=false - SEND_EMAILS=false
编写一个新的 development.yml 文件,使用 common.yml 中的 webapp 服务进行扩展。
# development.ymlweb: extends: file: common.yml service: webapp ports: - "8000:8000" links: - db environment: - DEBUG=truedb: image: postgres
后者会自动继承 common.yml 中的 webapp 服务及相关环节变量。
**
**
net
设置网络模式。使用和 docker client 的 --net 参数一样的值。
net: "bridge"net: "none"net: "container:[name or id]"net: "host"
**
**
pid
跟主机系统共享进程命名空间。打开该选项的容器可以相互通过进程 ID 来访问和操作。
pid: "host"
dns
配置 DNS 服务器。可以是一个值,也可以是一个列表。
dns: 8.8.8.8dns: - 8.8.8.8 - 9.9.9.9
cap_add, cap_drop
添加或放弃容器的 Linux 能力(Capabiliity)。
cap_add: - ALLcap_drop: - NET_ADMIN - SYS_ADMIN
**
**
dns_search
配置 DNS 搜索域。可以是一个值,也可以是一个列表。
dns_search: example.comdns_search: - domain1.example.com - domain2.example.com
**
**
working_dir, entrypoint, user, hostname, domainname, mem_limit, privileged, restart, stdin_open, tty, cpu_shares
这些都是和 docker run 支持的选项类似。
八、安全
8.1 内核命名空间
当使用 docker run 启动一个容器时,在后台 Docker 为容器创建一个独立的命名空间和控制集合。命名空间踢空了最基础的也是最直接的隔离,在容器中运行的进程不会被运行在主机上的进程和其他容器发现和作用。
8.2 控制组
控制组是 Linux 容器机制的另一个关键组件,负责实现资源的审计和限制。
它提供了很多特性,确保哥哥容器可以公平地分享主机的内存、CPU、磁盘IO等资源;当然,更重要的是,控制组确保了当容器内的资源使用产生压力时不会连累主机系统。
8.3 内核能力机制
能力机制是 Linux 内核的一个强大特性,可以提供细粒度的权限访问控制。 可以作用在进程上,也可以作用在文件上。
例如一个服务需要绑定低于 1024 的端口权限,并不需要 root 权限,那么它只需要被授权 net_bind_service 能力即可。
默认情况下, Docker 启动的容器被严格限制只允许使用内核的一部分能力。
使用能力机制加强 Docker 容器的安全有很多好处,可以按需分配给容器权限,这样,即便攻击者在容器中取得了 root 权限,也不能获取宿主机较高权限,能进行的破坏也是有限的。
参考资料
https://docs.docker.com/engine/reference/commandline/images/
http://www.dockerinfo.net/
]]>